Leveraging Power of Generative AI for Business: The Intelligence Solution Tech Stack
Harness Generative AI's potential in business with a robust IaaS stack ensuring streamlined adoption, ethical deployment, and strategic integration for innovation.


A discussion of a chart created by Insight Partners
Advancements in machine learning are ushering in a new era of technological transformation. At the epicenter of this seismic shift is Generative AI, a branch of AI that's pushing the boundaries of what machines can create. As businesses seek to leverage these potent tools, a robust MLOps (Machine Learning Operations) tech stack becomes essential. Not only does it streamline the adoption of these innovations, but it ensures they are deployed reliably and ethically within an enterprise.
The complexities of integrating a pre-trained Language Model (LLM) into specific applications are manifold, requiring meticulous planning and strategic foresight.
That is why when I stumbled upon this graph - it was too important not to pause and break it down for the AI-curious community. We leverage many of the tools listed in the chart as well as many open source technologies.
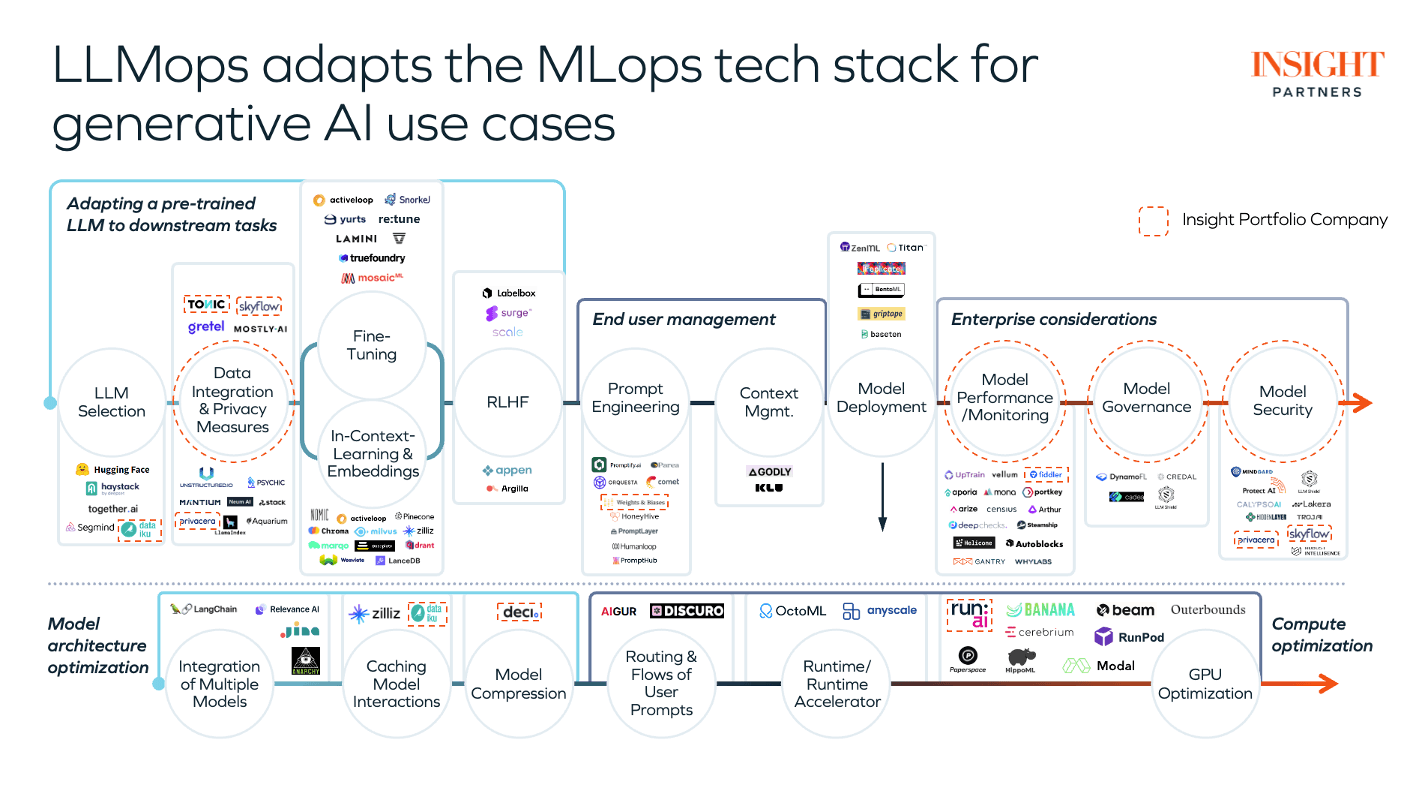
LLM Selection: The Foundation of Generative AI
When it comes to big data, no two words ring louder than 'personalization' and 'efficiency.' Selecting the right LLM lays the groundwork for these principles. Whether it's GPT-4's linguistic prowess or Hermes contextual understanding, each LLM comes with its unique capabilities, catering to varied use cases. On HuggingFace alone - there are 400,000 available open-source models to use & combine to build your solution.
Data Integration & Privacy Measures: The Ethical Compass
Vital to the integrity of any AI system is how it integrates data while safeguarding your business's and clients privacy. A fortress of techniques like anonymization and differential privacy ensures the sanctity of personal information, a testament to the conscientious use of technology. This layer of the tech stack does more than process data; it instills trust and complies with the stringent regulations of today's digital age. At MPR, we build solutions built around privacy - for example Ask Alpha has no user-tracking outside of basic token use. We do this because what you do with the tool is none of our concern - our job is to provide the best managed generative AI experience possible.
Fine-Tuning: Tailoring Intelligence to Fit
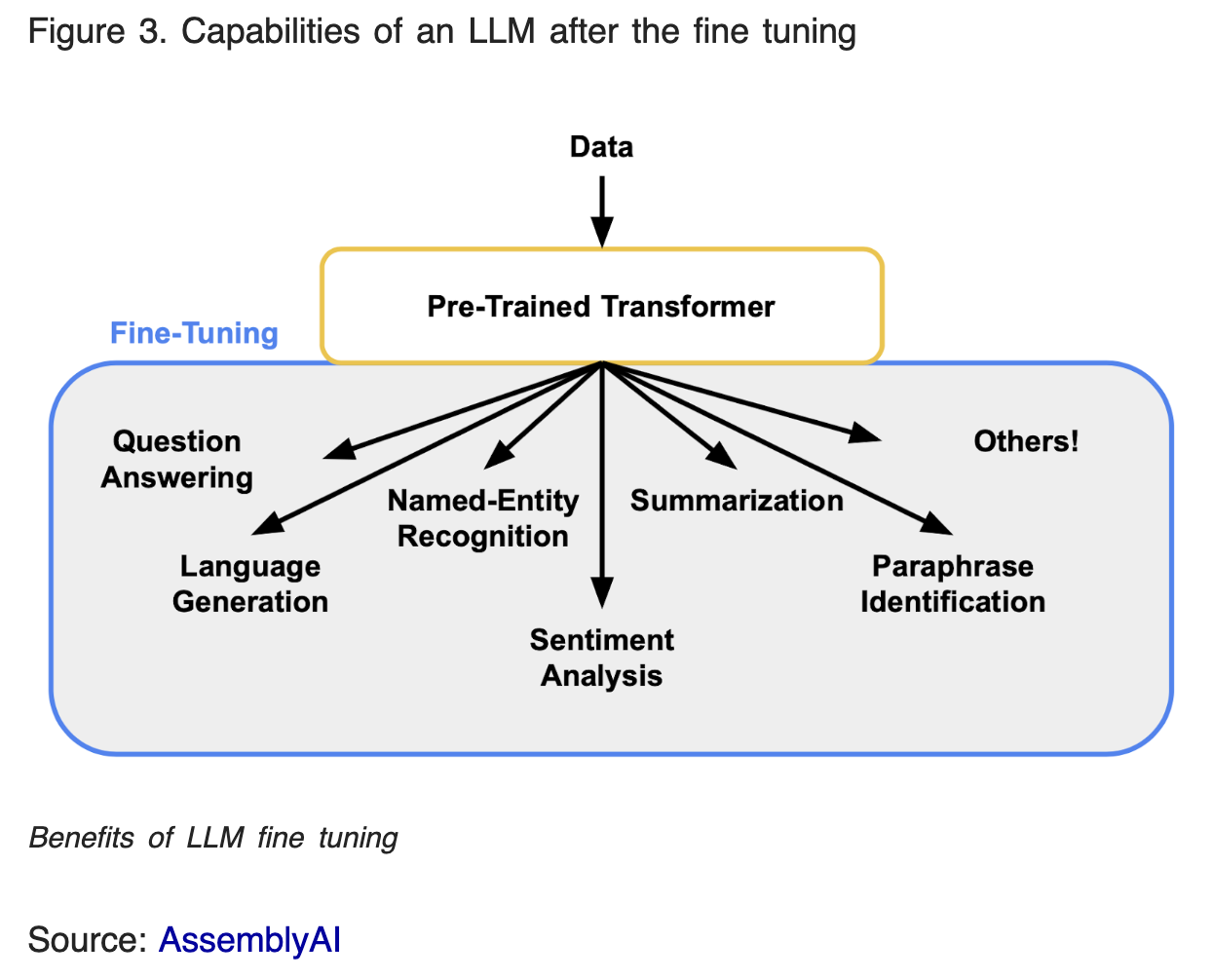
Akin to a tailor customizing a suit, fine-tuning adjusts an LLM to the intricacies of a use case. By training it further on domain-specific data, this customization process refines the broad capabilities of an LLM into a sharp tool adept at specific tasks—transforming generic intelligence into specialized wisdom. This stage is critical to differentiating your output from the competition.
In-Context Learning & Embeddings: Decoding the Subtleties
As a linguist interprets language nuances, contextual learning and embeddings enable LLMs to grasp the subtleties of their tasks, bridging the gap between raw data and a model's perception. These mechanisms convert information into a language of neural patterns that a machine can understand and learn from. For our service - Ask Alpha, we leverage a proprietary 2.5M Token embedded database on top of a base model like OpenAI to dramatically improve business results for our users.
RLHF: The Evolutionary Touch
Not all teachers are human, and not all students sit in classrooms—some learn through the sophisticated dance of algorithms and feedback. Reinforcement Learning from Human Feedback (RLHF) represents this evolutionary approach to model training, where user interactions sculpt a model’s intelligence, enabling it to iterate towards perfection. Hosted AI Providers like OpenAI and Anthropic perform RLHF which means every query you provide them is used to improve the system with a tradeoff of a risk of exposing query information. Self-hosted LLMs could be build without RLHF.
End-User Management: The Conductor of Interactions
Fine-tuning isn't merely about machine learning; it's also about user interaction. End-user management is the conductor of this orchestra, ensuring that each prompt and context harmonizes to deliver the smoothest user experience—a symphony of well-orchestrated prompts, contexts, and deployments. The user should be trained on prompt engineering basics as well as practice human-machine-articulation (HMA).
Model Architecture Optimization: Crafting the Engine for Efficiency
In the race for computational efficiency, Model Architecture Optimization is the pitstop where all tweaks are made to enhance performance under the hood. It's a meticulous effort of calibrating the LLM engine for a more robust, leaner, and faster entity.
Integration of Multiple Models: The Art of Coordination
Sometimes, excellence lies in unity. Integrating various models is akin to arranging an ensemble—each must be attuned to play harmoniously. This step is vital for creating multifaceted AI solutions, showcasing a meticulous balance of expertise. With Ask Alpha, we let the users choose between multiple curated models that are tested daily for alignment and output consistency.
Caching Model Interactions: The Fast-Access Memory Lane
Imagine a library where the most sought-after books are always at the front desk—that's what caching does for model interactions. This stage optimizes response times by holding onto frequently requested data, a form of fast-access memory that underpins service efficiency. This would be particularly useful in business cases like sales or service empowerment where similar requests are processed daily.
Model Compression: Fitting Brilliance into a Compact Form
The genius of generative AI, compressed without compromising on its smarts, makes deployment feasible in even the most resource-stringent environments. Model Compression champions the concept of doing more with less, preserving AI capacity while shrinking its digital footprint. General models have the requirement of containing data which includes the entire internet - this computational load is significant. For general knowledge questions - it's required. For more specific tasks, many would consider it overkill however general models typically outperform task-specific models. This is one of the reasons why we do not recommend our clients train their own models - outside of ego, it's generally a waste of time.
Routing & Flows of User Prompts: Paving The Path for User Actions
Imagine AI as a city, and user prompts as traffic—Routing & Flows ensure that each interaction finds the optimal path to its destination. This layer ensures that the AI's responses and user pathways are clear, direct, and purposeful. With these types of services, you can daisy-chain prompt+responses together for more streamlined automation.
Runtime/Runtime Accelerator: The Arena of AI Performance
Runtime is where AI comes alive, and accelerators are its steroids. This performance-driven aspect focuses on creating an environment that extracts the maximum potential from each machine learning model, instrumental in elevating functional speed and responsiveness.
Compute Optimization: Maximizing Your Digital Horsepower
Just as a finely tuned sports car uses fuel efficiently, Compute Optimization makes sure every tick of the processor counts. By leveraging tools such as GPU optimization, this facet of the MLOps stack fine-tunes the raw energy that drives training and inference tasks, ensuring a sleek, economical performance.
Enterprise Considerations: The Pillars of Sustainability
These broad categories encapsulate the bedrock for deploying Generative AI at scale:
- Model Performance/Monitoring: The vigilant watch over AI deliverables, ensuring they stand up to the highest standards of business needs.
- Model Governance: The constitution for AI deployment—a charter that underscores ethical, transparent, and accountable use of technology.
- Model Security: The shield and sword that stand guard against digital threats, preserving the sanctity of AI operations.
In conclusion, this visual graph isn't just a roadmap; we see it as a blueprint for future-proofing businesses in the AI domain. It ensures generative AI applications are built and maintained to scale, designed for precision and wrapped in the highest standards of governance, security, and efficiency.
As we chart the course in this brave new world of AI, leveraging such a comprehensive MLOps tech stack is not just a competitive advantage—it's an operational imperative.